What Does Spark Replace Exactly?
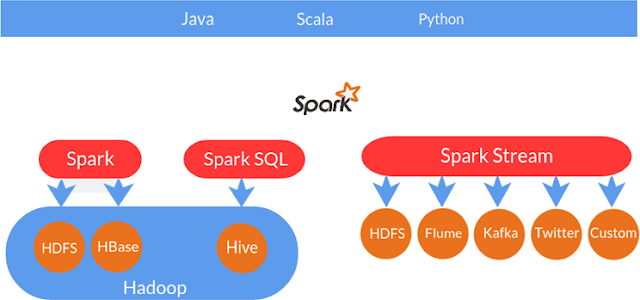
Spark and Storm are the two cousins companies that provide abstractions over Hadoop. Hadoop is a part of apache project; it is an open source distributed java based programming framework. It supports the storage and programming of a large data set in distributed computing environment. It is sponsored by Apache software foundation. Spark and storm makes it easy to use this programming framework in some easy ways. Hadoop can take in lots of data and allows you to build a scalable system and do analytics on that data. If you successfully build it in Hadoop in right way, you can increase the capacity of your system by adding more servers. This helps you to spin your machines depending on the size of your load. Hadoop is practically flexible; you can use it in many different ways. Due to this it is also hard to work with. Hadoop consists of Hadoop common package. This package consists of necessary Java scripts and JAR files that are needed to start Hadoop. Every file sh...